The next step
An early classic benchmark test for Beowulf clusters was "Sum of Squares" or SIGMASQR.C looks something like this:
10 Clr Time
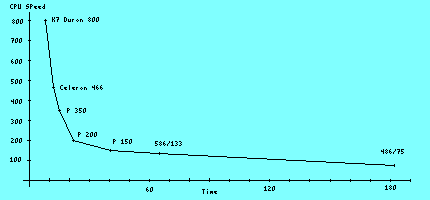
On my 486DX/4 UBASIC did this:
When I = 100,000 the time is 1.775 seconds (QBASIC took
1 min, 13 sec.)
When I = 1,000,000 the time is 18 seconds
486DX/4 75Mhz 3 minutes, 4 seconds
When I = 100,000,000 the time is 32 minutes, 5 seconds
Note: In the above test QBASIC and both QBs only calculate as 3.33382+17, and UBASIC gives a decimal answer.
I did not run it at 100 billion, but you can see why. I don't know how the task was divided among the nodes in the original benchmark, but I would do this for two nodes:
Line 20 in node 1 would be: For I=1 to 100000000 step 2
Line 20 in node 2 would be: For I=2 to 100000000 step 2
This way, one node does the odd numbers, the other node the even. More nodes, the bigger the step. The SUM would be sent to the console to be added together.
On the Pentium 350, using step 2 (above) dropped the time from 18.8 seconds to 7.5 seconds, less than half the time. Step 3, 5 seconds. Step 4, 3.75 seconds. Four P350s could out perform the 1.8 GHz machine. Of course, it would be nice to have four 1.8 GHz machines, but older Pentiums are dropping to flea market prices.
When you write you application this way, the communication is minimal. If the nodes sent each square to the console to be added, the communication load would be tremendous.
NOTE: In real life, there are times when more than a hundred nodes are available in a (Linux) cluster, but 35 to 40 can do it faster.
Faster processors are NOT the answer. Two machines were benched using another program, one a 500 MHz the other, 2 GHz. The 2 Gig machine was less than twice as fast, not four times faster. The same applies to muti-processor machines.