|
|
Beowulf Supercomputing Clusters for DOS
Do it yourself in an evening for under $10.
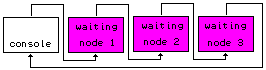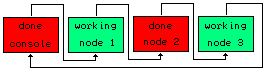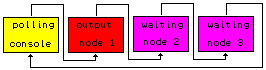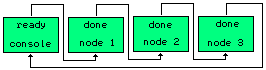
A project meant to make
supercomputing available to the
experimenter,
amateur scientist, small laboratories and the inventor.
Build your own
Follow the links below for a step-by-step look at your own low-cost supercomputing cluster. If you have two or more old DOS machines, the cost can probably be kept under $10. The machines don't need a lot of memory or even a hard drive, but they must have a working parallel port.
The platform for the cluster is UBASIC 8.8F, which is an ultra-precision high speed language written entirely in assembly language and downloadable for free. I prefer FreeDOS as the operating system as UBASIC runs significantly faster on it than it does on MS-DOS.
Features
Communication is a full 8 bits wide with 100% handshaking.
Everything fits on one floppy with plenty of room to spare.
Transmission speed adjusts automatically to the port.
Formulas to be executed can be sent to nodes.
Calculations to 2600 decimal places.
Chaining possible between nodes.
Nodes can be easily added.
Built in diagnostics.
Easy to use.
It's free.
Constructing the connection cable For two PCs
Constructing a ring cable For more than two PCs
Download 32bit Download 16bit Version 2.01 October 11, 2002
Download FreeDOS
OK, I got it working. Now what?
My other projects

Folding dinghy plans: Here
Bill mailto:dosbeowulf@lycos.com
Last update September 4, 2006
  |